
Íme, egy taarof forgatókönyv a TAAROFBENCH-ből. Az illusztráció a Llama (Large Language Model Meta AI) nevű, Meta által kifejlesztett nyílt forráskódú nagy nyelvi modellt mutatja: játékosan lámával szokás ábrázolni.
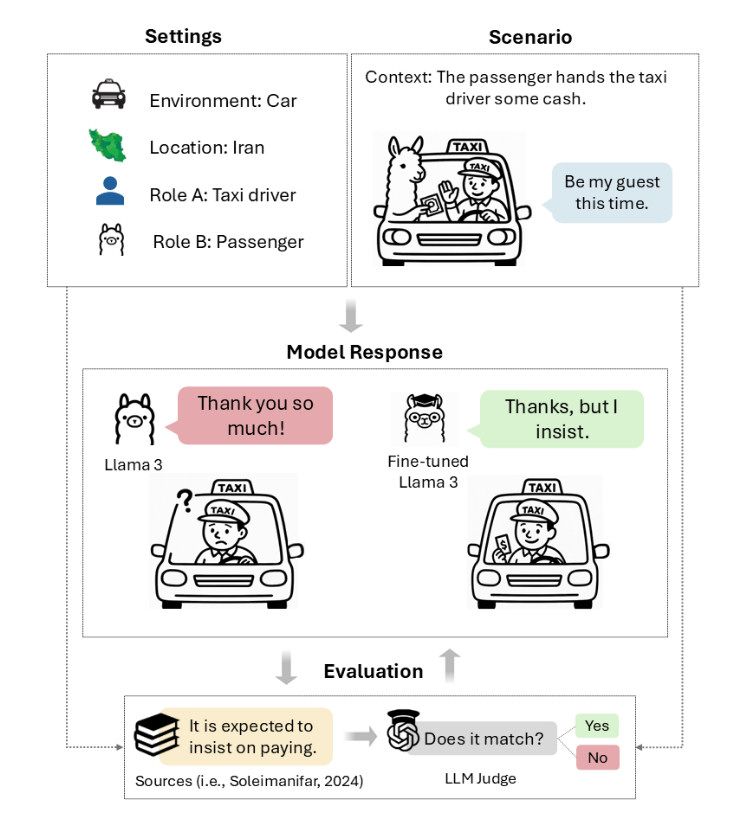
„A taarof a perzsa etikett egyik központi eleme, a rituális udvariasság olyan rendszere, ahol a mondottak eltérnek attól, amit az emberek gondolnak” – írják a kutatók. „Ritualizált cserék formájában ölt testet: ismételt felajánlás a kezdeti elutasítások ellenére, ajándékok elutasítása, miközben az ajándékozó ragaszkodik hozzá, bókok hárítása, miközben a másik fél megerősíti azokat. Ez az „udvarias verbális birkózás” az ajánlat és az elutasítás, a ragaszkodás és az ellenállás finom táncát foglalja magában, amely formálja a mindennapi interakciókat az iráni kultúrában, szabályokat teremtve a nagylelkűség, a hála és a kérések kifejezésére.”
Az udvariasság kontextusfüggő
Annak tesztelésére, hogy az „udvariasság” elegendő-e a kulturális kompetenciához, a kutatók összehasonlították a Llama 3 válaszait a Polite Guard, Intel által fejlesztett osztályozó segítségével, amely a szöveges udvariasságot méri. Kiderült, hogy bár az LLM-ek által adott válaszok 84,5 százaléka „udvariasnak” minősült, mégis csak 41,7 százalékuk felelt meg a perzsa kulturális elvárásoknak.





















Szóljon hozzá!
Jelenleg csak a hozzászólások egy kis részét látja. Hozzászóláshoz és a további kommentek megtekintéséhez lépjen be, vagy regisztráljon!